Overstocking van voorraden kan zowel de financiële stabiliteit als de operationele efficiëntie schaden. Wanneer een organisatie overstocking heeft, legt het kapitaal vast in overtollige voorraden die mogelijk niet verkocht worden, wat de opslagkosten en het risico op veroudering van de voorraad verhoogt. Bovendien hadden de fondsen die gebruikt werden om de overtollige voorraad te kopen beter geïnvesteerd kunnen worden in andere gebieden van het bedrijf, zoals marketing of onderzoek en ontwikkeling. Overstocking belemmert ook de cashflow, omdat geld vastzit in voorraden in plaats van beschikbaar is voor onmiddellijke operationele behoeften. Effectief voorraadbeheer is cruciaal voor het behouden van een gezonde balans en het verzekeren dat middelen optimaal worden toegewezen. Hier volgt een diepgaande verkenning van de belangrijkste oorzaken van overstocking, hun implicaties en mogelijke oplossingen.
1 Onjuiste vraagvoorspelling
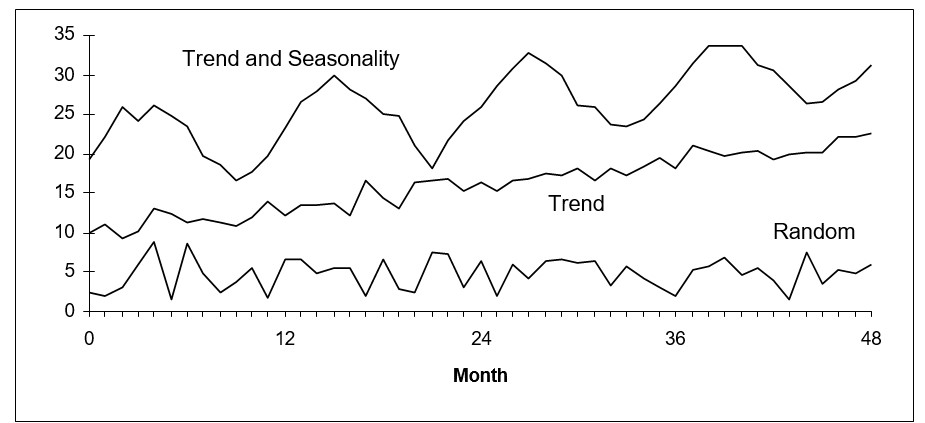
Een van de belangrijkste oorzaken van overstocking is onnauwkeurige vraagvoorspelling. Wanneer bedrijven vertrouwen op verouderde voorspellingsmethoden of onvoldoende gegevens, kunnen ze de vraag gemakkelijk overschatten, wat leidt tot overstocking. Een goed voorbeeld is de kledingindustrie, waar modetrends snel kunnen veranderen. Een bekend modemerk kreeg onlangs te maken met uitdagingen nadat het de vraag naar een nieuwe kledinglijn had overschat op basis van gebrekkige data-analyse, wat leidde tot onverkochte voorraad.
Om dit probleem aan te pakken, kunnen bedrijven nieuwe technologieën implementeren die automatisch de beste prognosemethoden voor de gegevens selecteren, waarbij trends en seizoenspatronen worden opgenomen om nauwkeurigheid te garanderen. Door de nauwkeurigheid van de prognose te verbeteren, kunnen bedrijven hun inventaris beter afstemmen op de werkelijke vraag, wat leidt tot nauwkeuriger voorraadbeheer en minder overstockscenario's. Een hardwareretailer die Smart Demand Planner gebruikte, verminderde bijvoorbeeld prognosefouten met 15%, wat het potentieel voor aanzienlijke verbetering in voorraadbeheer aantoont.
2 Onjuist voorraadbeheer
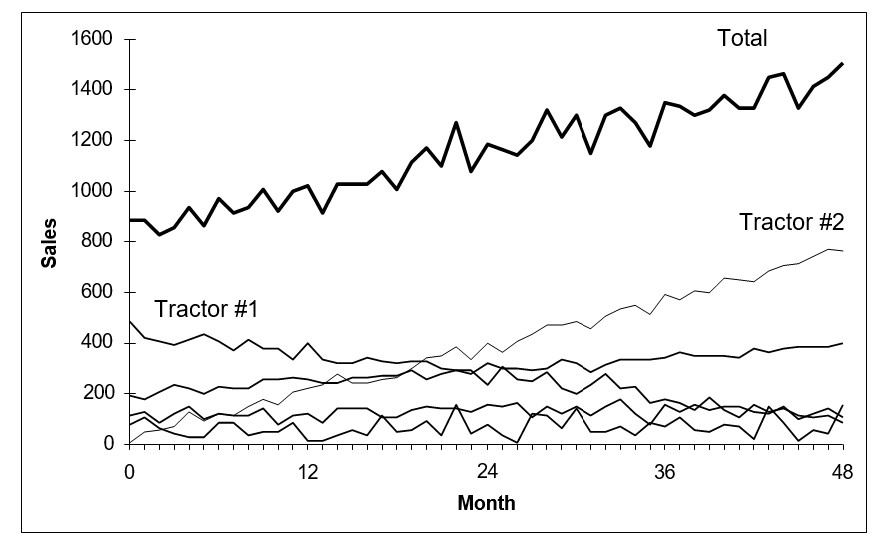
Effectief voorraadbeheer is fundamenteel om overstocking te voorkomen. Zonder nauwkeurige systemen om voorraadniveaus bij te houden, kunnen bedrijven overtollige voorraad bestellen en hogere kosten maken. Dit probleem komt vaak voort uit afhankelijkheid van spreadsheets of inefficiënte ERP-systemen die geen realtime data-integratie hebben.
State-of-the-art technologieën bieden realtime inzicht in voorraadniveaus, waardoor bedrijven bestelprocessen kunnen automatiseren en optimaliseren. Een groot elektriciteitsbedrijf had te maken met uitdagingen bij het behouden van de beschikbaarheid van serviceonderdelen zonder overbevoorrading, waarbij meer dan 250.000 onderdeelnummers werden beheerd in een divers netwerk van elektriciteitsopwekkings- en distributiefaciliteiten. Het bedrijf verving zijn verouderde systeem door Smart IP&O en integreerde het in realtime met hun Enterprise Asset Management (EAM)-systeem. Smart IP&O stelde het nutsbedrijf in staat om 'what-if'-scenario's te gebruiken, digitale tweelingen van alternatieve voorraadbeleid te creëren en prestaties te simuleren op basis van belangrijke prestatie-indicatoren, zoals voorraadwaarde, serviceniveaus, vulpercentages en tekortkosten. Hierdoor kon het nutsbedrijf gerichte aanpassingen doen aan hun voorraadparameters, die vervolgens werden geïmplementeerd in hun EAM-systeem, wat leidde tot optimale aanvullingen van reserveonderdelen.
Het resultaat was significant: een vermindering van de voorraad met $9 miljoen, waardoor er geld en waardevolle magazijnruimte vrijkwam, terwijl de beoogde serviceniveaus van meer dan 99% werden gehandhaafd.
3 overdreven optimistische verkoopprognoses
Bedrijven, met name die in groeifases, kunnen hogere verkopen voorspellen dan ze realiseren, wat leidt tot overtollige voorraad die bedoeld is om te voldoen aan de verwachte vraag die nooit werkelijkheid wordt. Een voorbeeld hiervan is het recente geval met een fabrikant van elektrische voertuigen die hoge verkopen voor zijn vrachtwagen voorspelde, maar te maken kreeg met vertragingen in de productie en een lagere vraag dan verwacht, wat resulteerde in een overschot aan componenten en onderdelen. Deze verkeerde berekening leidde tot hogere opslagkosten en beperkte financiële middelen.
Een ander bedrijf in de automotive aftermarket had moeite om onderdelen die af en toe werden gevraagd nauwkeurig te voorspellen, wat vaak resulteerde in overstocking en stockouts. Met behulp van AI-gestuurde technologie kon het bedrijf backorders en verloren verkopen aanzienlijk verminderen, met een verbetering van de vulpercentages van 93% naar 96% binnen slechts drie maanden. Door gebruik te maken van Smart IP&O-prognosetechnologieën kon het bedrijf nauwkeurige schattingen genereren van de cumulatieve vraag over doorlooptijden, wat een beter zicht bood op potentiële vraagscenario's. Dit zorgde voor geoptimaliseerde voorraadniveaus, lagere opslagkosten en verbeterde financiële efficiëntie door de voorraad af te stemmen op de werkelijke vraag.
4 Kortingen bij bulkaankopen
De aantrekkingskracht van kostenbesparingen door bulkaankopen kan bedrijven ertoe aanzetten om meer te kopen dan nodig is, waardoor kapitaal en opslagruimte worden vastgelegd. Dit leidt vaak tot opslagproblemen wanneer overtollige voorraad wordt besteld om korting te krijgen.
Om deze uitdaging aan te gaan, moeten bedrijven de voordelen van bulkkortingen afwegen tegen de kosten van het aanhouden van overtollige voorraad. Technologie van de volgende generatie kan helpen de meest kosteneffectieve inkoopstrategie te identificeren door directe besparingen in evenwicht te brengen met opslagkosten op de lange termijn. Door Smart IP&O te implementeren, kon MNR de voorraadvereisten nauwkeurig voorspellen en zijn voorraadbeheerprocessen optimaliseren. Dit leidde tot een vermindering van 8% in de onderdelenvoorraad, waardoor een hoog klantenserviceniveau van 98,7% werd bereikt en de voorraadgroei voor nieuwe apparatuur werd teruggebracht van een geprojecteerde 10% naar slechts 6%.
5 Seizoensgebonden Vraagschommelingen
Moeilijkheden bij het afstemmen van de voorraad op de seizoensgebonden vraag kunnen leiden tot overtollige voorraad zodra de piekverkoopperiode voorbij is. Speelgoedfabrikanten kunnen bijvoorbeeld te veel speelgoed met een vakantiethema produceren, alleen om na de feestdagen met een lage vraag te worden geconfronteerd. De mode-industrie ervaart vaak soortgelijke uitdagingen, waarbij bepaalde stijlen verouderd raken naarmate de seizoenen veranderen. De nieuwste technologieën kunnen bedrijven helpen om seizoensgebonden vraagverschuivingen te anticiperen en de voorraadniveaus dienovereenkomstig aan te passen. Door eerdere verkoopgegevens te analyseren en toekomstige trends te voorspellen, kunnen bedrijven zich beter voorbereiden op seizoensgebonden schommelingen, het risico op overbevoorrading minimaliseren en de voorraadomzet verbeteren.
6 Variabiliteit in de levertijd van leveranciers
Onbetrouwbare levertijden van leveranciers kunnen leiden tot overstocking als buffer tegen vertragingen. Als levertijden verbeteren of de vraag onverwachts afneemt, kunnen bedrijven overtollige voorraad hebben. Een distributeur van auto-onderdelen kan bijvoorbeeld onderdelen opslaan om vertragingen bij leveranciers te beperken, maar dan merken ze dat de levertijden plotseling verbeteren.

Geavanceerde technologie kan helpen door realtime data en voorspellende analyses te leveren om de variabiliteit van de doorlooptijd beter te beheren. Deze tools stellen bedrijven in staat om hun orders dynamisch aan te passen, waardoor de behoefte aan overmatige veiligheidsvoorraad afneemt.
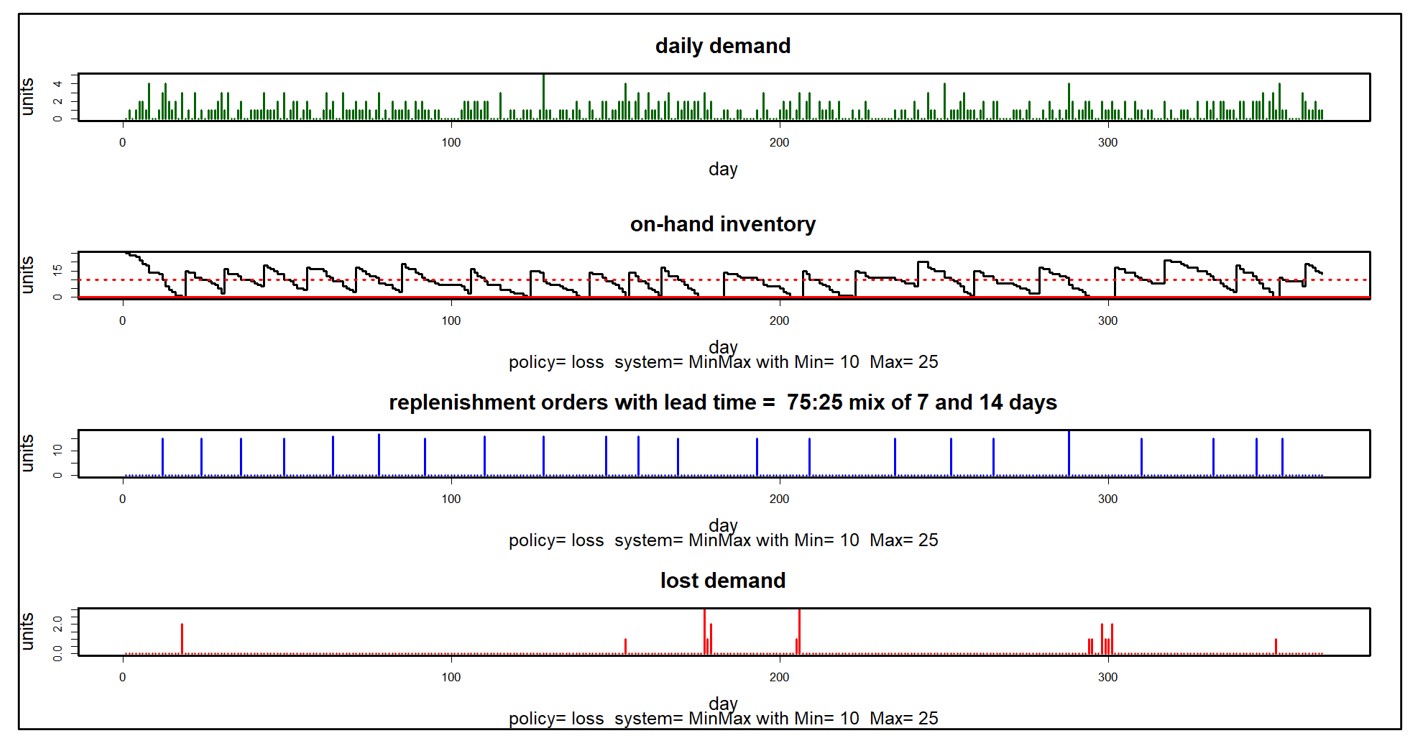
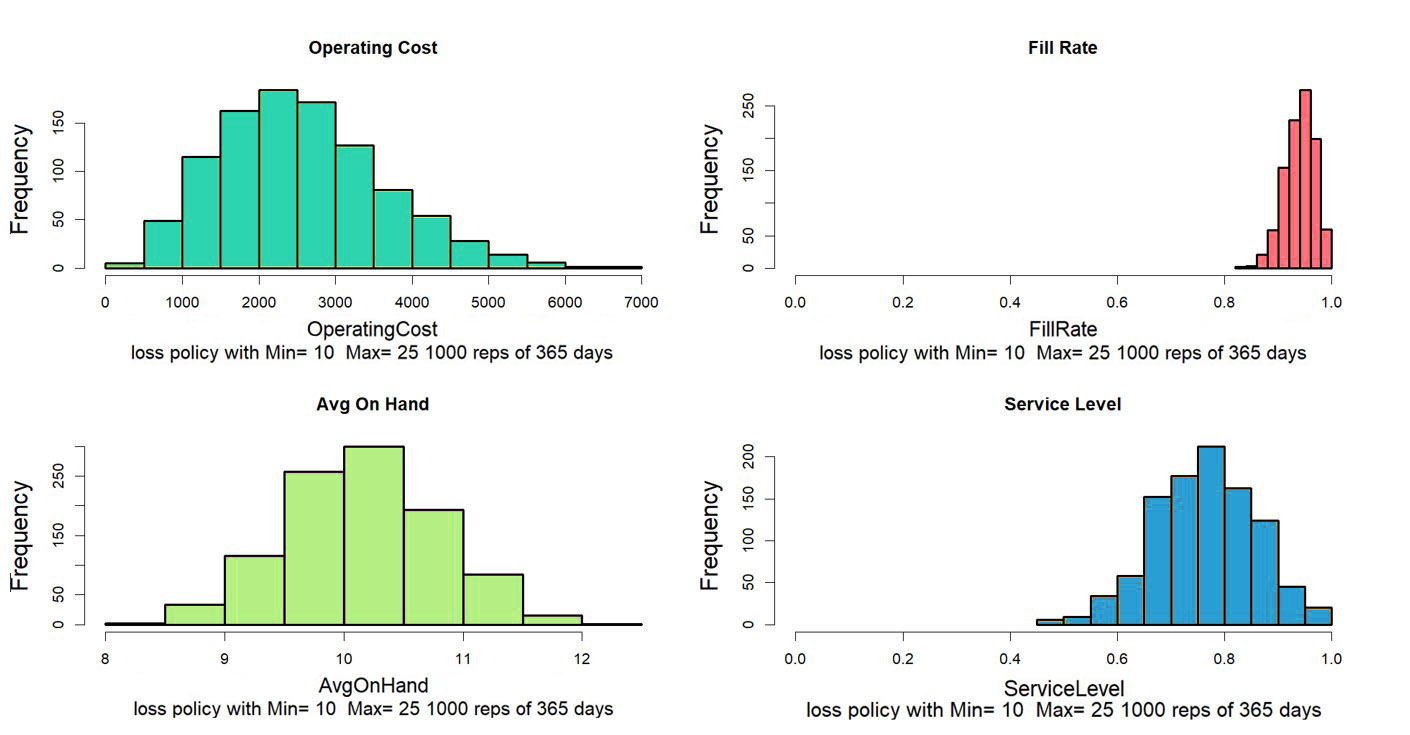
7 Onvoldoende voorraadbeleid
Verouderde of onjuiste voorraadbeleidsregels, zoals foutieve Min/Max-instellingen, kunnen leiden tot overbestelling. Door echter moderne technologie te gebruiken om voorraadbeleidsregels regelmatig te controleren en bij te werken, wordt ervoor gezorgd dat ze aansluiten bij de huidige bedrijfsbehoeften en marktomstandigheden. Door beleid up-to-date te houden, kunnen bedrijven het risico op overstocking als gevolg van procedurele fouten verminderen. Een recente casestudy liet zien hoe een grote retailer Smart IP&O gebruikte om voorraadbeleidsregels te herzien, wat resulteerde in een 15%-reductie in overstock.
8 Promoties en marketingcampagnes
Een verkeerde afstemming tussen marketinginspanningen en de werkelijke vraag van klanten kan ertoe leiden dat bedrijven de impact van promoties overschatten, wat resulteert in onverkochte voorraad. Een cosmeticabedrijf kan bijvoorbeeld een product in beperkte oplage overproduceren, in de verwachting van een hoge vraag die niet uitkomt. Door Smart IP&O in te zetten, kunnen marketinginitiatieven worden afgestemd op realistische vraagverwachtingen, waardoor overtollige voorraad wordt vermeden. Door marketingplannen te integreren met vraagvoorspellingen, kunnen bedrijven hun promotionele strategieën optimaliseren om beter aan te sluiten bij de werkelijke interesse van klanten.
9 Angst voor voorraadtekorten
Bedrijven houden vaak hogere voorraadniveaus aan om voorraadtekorten te voorkomen, wat kan leiden tot omzetverlies en ontevreden klanten. Deze angst kan bedrijven ertoe aanzetten om te veel voorraad aan te leggen als vangnet, vooral in sectoren waar klanttevredenheid en -behoud cruciaal zijn. Een opvallend voorbeeld is een grote winkelketen die zijn voorraad huishoudelijke artikelen aanzienlijk uitbreidde om voorraadtekorten te voorkomen. Hoewel deze strategie aanvankelijk hielp om aan de vraag van klanten te voldoen, resulteerde dit later in overtollige voorraad toen de aankooppatronen van consumenten zich stabiliseerden. Deze overstocking droeg bij aan een winstdaling van bijna 90% in het tweede kwartaal, grotendeels als gevolg van afprijzingen en het opruimen van overtollige voorraad.
Om dergelijke situaties te beperken, kunnen bedrijven geavanceerde voorraadplannings- en optimalisatietools gebruiken om nauwkeurige vraagvoorspellingen te doen. Een toonaangevende elektronicafabrikant gebruikte bijvoorbeeld de Smart IP&O-oplossing om de voorraadniveaus te verlagen met 20% zonder dat dit gevolgen had voor de serviceniveaus. Dit verlaagde effectief de kosten en zorgde ervoor dat de klanttevredenheid behouden bleef door te zorgen dat ze de juiste hoeveelheid voorraad bij de hand hadden.
10 Overcompensatie voor problemen in de toeleveringsketen
Bedrijven kunnen te veel voorraad aanleggen om zich te beschermen tegen voortdurende verstoringen in de toeleveringsketen, maar dit kan leiden tot opslagproblemen. Een technologiebedrijf kan bijvoorbeeld componenten opslaan om mogelijke problemen in de toeleveringsketen te voorkomen, wat resulteert in overtollige voorraad en hogere kosten. Geavanceerde systemen kunnen bedrijven helpen om beter te anticiperen op en te reageren op uitdagingen in de toeleveringsketen, door de behoefte aan veiligheidsvoorraad in evenwicht te brengen met het risico van te veel voorraad. Een technologiebedrijf gebruikte Smart IP&O om zijn voorraadstrategie te stroomlijnen, waarbij de overtollige voorraad werd verminderd tegen 20% en de veerkracht van de toeleveringsketen behouden bleef.
11 Lange levertijden en onbetrouwbare leveranciers
Lange doorlooptijden en onbetrouwbare leveranciers kunnen ertoe leiden dat bedrijven meer voorraad bestellen dan nodig is om potentiële leveringstekorten te dekken. Minder kritieke artikelen waarvan wordt voorspeld dat ze een zeer hoog serviceniveau bereiken, vertegenwoordigen echter kansen om de voorraad te verminderen. Door lagere serviceniveaus te targeten voor minder kritieke artikelen, zal de voorraad na verloop van tijd de "juiste grootte" hebben voor het nieuwe evenwicht, waardoor de opslagkosten en de waarde van de voorraad afnemen. Een groot openbaarvervoersysteem verminderde de voorraad met meer dan $4.000.000 terwijl het serviceniveau werd verbeterd met behulp van onze geavanceerde technologie.
12 Gebrek aan realtime inzicht in de voorraad
Zonder realtime inzicht in de voorraad bestellen bedrijven vaak meer voorraad dan nodig is, wat leidt tot inefficiëntie en hogere kosten. Smart IP&O stelde Seneca-bedrijven in staat om de vraag op elke voorraadlocatie te modelleren en, met behulp van servicelevelgestuurde planning, te bepalen hoeveel er moet worden opgeslagen om het vereiste serviceniveau te bereiken. Door verschillende scenario's uit te voeren en te vergelijken, kunnen ze eenvoudig optimale voorraadbeleidsregels definiëren en bijwerken voor elke technische ondersteuningsvertegenwoordiger en voorraadruimten.
De software heeft veldtechnici bewijs geleverd dat ze voorheen niet hadden, door hun werkelijke verbruik, de frequentie van het gebruik van onderdelen en de reden voor het voorraadbeleid te tonen, waarbij 90% werd gebruikt als de beoogde serviceniveaunorm. Veldtechnici hebben het gebruik ervan omarmd, met significante resultaten: de voorraad "Zero Turns" is gedaald van $400K tot minder dan $100K, de "First Fix Rate" overschrijdt 90% en de totale voorraadinvestering is met meer dan 25% gedaald, van $11 miljoen tot $ 8 miljoen .
Concluderend vormt overstocking een ernstige bedreiging voor de winstgevendheid en efficiëntie van bedrijven, wat leidt tot hogere opslagkosten, vastgelopen kapitaal en mogelijke veroudering van goederen. Deze problemen kunnen de middelen belasten en het vermogen van een bedrijf om te reageren op marktveranderingen beperken. Overstocking kan echter effectief worden beheerd door de oorzaken ervan te begrijpen, zoals onnauwkeurige vraagvoorspellingen, langere doorlooptijden en onbetrouwbare leveranciers. Het implementeren van robuuste AI-gestuurde oplossingen zoals Smart IP&O kan bedrijven helpen voorraadniveaus te optimaliseren, overtollige voorraad te verminderen en de operationele efficiëntie te verbeteren. Door geavanceerde prognose- en voorraadoptimalisatietools te benutten, kunnen bedrijven de juiste balans vinden tussen het voldoen aan de vraag van klanten en het minimaliseren van voorraadgerelateerde kosten.