Een nieuwe maatstaf die we de "Attentie-index" noemen, helpt voorspellers situaties te identificeren waarin "gegevens die zich slecht gedragen" automatische statistische voorspellingen kunnen verstoren (zie hiernaast). Het identificeert snel die items die waarschijnlijk de meeste kans hebben om prognoses te negeren, wat een efficiëntere manier biedt om zakelijke ervaring en andere menselijke intelligentie aan het werk te zetten om de nauwkeurigheid van prognoses te maximaliseren. Hoe werkt het?
Klassiek voorspellingsmethoden, zoals de verschillende smaken van exponentiële afvlakking en voortschrijdende gemiddelden, dringen aan op een sprong in het diepe. Ze vereisen dat we erop vertrouwen dat de huidige omstandigheden in de toekomst blijven bestaan. Als de huidige omstandigheden aanhouden, is het verstandig om deze extrapolatieve methoden te gebruiken - methoden die het huidige niveau, de trend, de seizoensgebondenheid en "ruis" van een tijdreeks kwantificeren en projecteren in de toekomst.
Maar als ze niet aanhouden, kunnen extrapolatieve methoden ons in de problemen brengen. Wat omhoog ging, kan ineens omlaag gaan. Wat vroeger rond het ene niveau was gecentreerd, kan plotseling naar een ander niveau springen. Of er kan iets heel vreemds gebeuren dat volledig uit het patroon is. In deze verrassende omstandigheden verslechtert de nauwkeurigheid van de prognoses, gaan voorraadberekeningen verkeerd en ontstaat er algemene onvrede.
Een manier om met dit probleem om te gaan, is te vertrouwen op complexere voorspellingsmodellen die rekening houden met externe factoren die de variabele bepalen die wordt voorspeld. Verkooppromoties proberen bijvoorbeeld kooppatronen te verstoren en in een positieve richting te bewegen, dus het opnemen van promotieactiviteiten in het prognoseproces kan de verkoopprognoses verbeteren. Soms kunnen macro-economische indicatoren, zoals het starten van huizen of inflatiepercentages, worden gebruikt om de nauwkeurigheid van prognoses te verbeteren. Maar complexere modellen vereisen meer gegevens en meer expertise, en ze zijn misschien niet bruikbaar voor sommige problemen, zoals het beheer van onderdelen of subsystemen, in plaats van afgewerkte goederen.
Als iemand vastloopt met behulp van eenvoudige extrapolatieve methoden, is het handig om een manier te hebben om items te markeren die moeilijk te voorspellen zijn. Dit is de Aandachtsindex. Zoals de naam al doet vermoeden, vereisen items die moeten worden voorspeld met een hoge Attention Index een speciale behandeling - op zijn minst een beoordeling en meestal een soort van prognoseaanpassing.
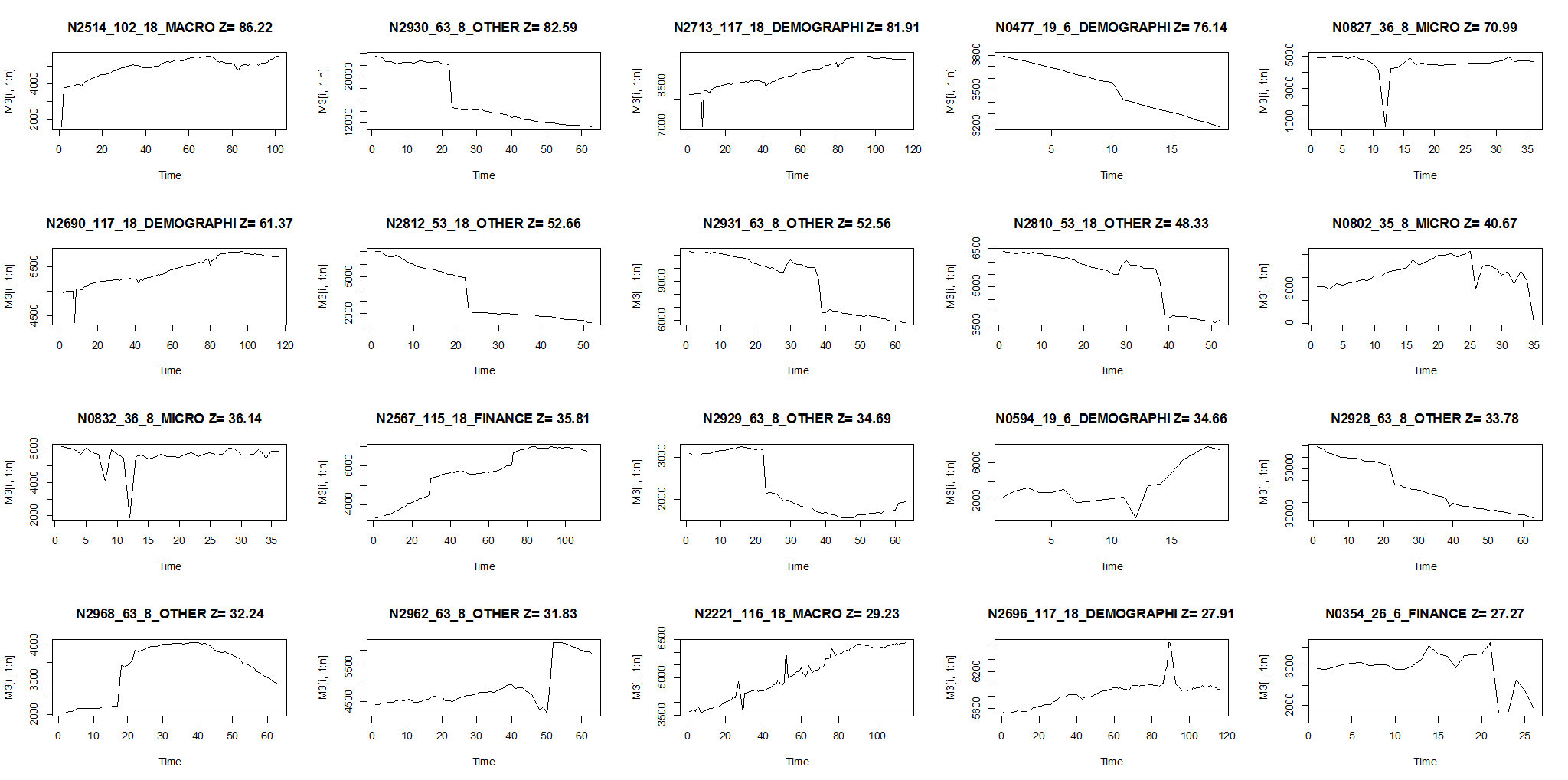
De Aandachtsindex detecteert drie soorten problemen:
Een uitbijter in de vraaggeschiedenis van een artikel.
Een abrupte verandering in het niveau van een item.
Een abrupte verandering in de trend van een artikel.
Met behulp van software zoals SmartForecasts™ kan de voorspeller omgaan met een uitbijter door deze te vervangen door een meer typische waarde.
Een abrupte verandering in niveau of trend kan worden verholpen door alle gegevens van vóór de "breuk" in het vraagpatroon uit de prognoseberekeningen weg te laten, ervan uitgaande dat het item is overgeschakeld naar een nieuw regime dat de oudere gegevens irrelevant maakt.
Hoewel geen enkele index perfect is, slaagt de Aandachtsindex er goed in om de aandacht te vestigen op de meest problematische vraaggeschiedenissen. Dit wordt aangetoond in de twee onderstaande figuren, die zijn gemaakt met gegevens van de M3 Competition, bekend in de prognosewereld. Figuur 1 toont de 20 items (van de 3.003 van de wedstrijd) met de hoogste Attention Index-scores; al deze hebben groteske uitschieters en breuken. Figuur 2 toont de 20 items met de laagste Attention Index-scores; de meeste (maar niet alle) items met lage scores hebben relatief goedaardige patronen.
Als u duizenden items te voorspellen heeft, zal de nieuwe Aandachtsindex zeer nuttig zijn om uw aandacht te richten op die items die het meest waarschijnlijk problematisch zijn.
Thomas Willemain, PhD, was mede-oprichter van Smart Software en is momenteel Senior Vice President for Research. Dr. Willemain is ook emeritus hoogleraar Industrial and Systems Engineering aan het Rensselaer Polytechnic Institute en als lid van de onderzoeksstaf van het Centre for Computing Sciences, Institute for Defence Analyses.

gerelateerde berichten

Op zoek naar problemen met uw voorraadgegevens
In deze videoblog wordt een cruciaal aspect van voorraadbeheer in de schijnwerpers gezet: de analyse en interpretatie van voorraadgegevens. De focus ligt specifiek op een dataset van een openbaar vervoersbedrijf met details over reserveonderdelen voor bussen.

Kan willekeur een bondgenoot zijn in de voorspellingsstrijd?
Wanneer we de complexe wereld van de logistiek proberen te begrijpen, speelt willekeur een cruciale rol. Dit introduceert een interessante paradox: in een realiteit waarin precisie en zekerheid worden gewaardeerd, zou de onvoorspelbare aard van vraag en aanbod daadwerkelijk als een strategische bondgenoot kunnen dienen?
De zoektocht naar nauwkeurige voorspellingen is niet alleen een academische oefening; het is een cruciaal onderdeel van operationeel succes in tal van sectoren. Voor vraagplanners die moeten anticiperen op de productvraag zijn de gevolgen van het goed of fout doen van de vraag van cruciaal belang. Daarom is het herkennen en benutten van de kracht van willekeur niet slechts een theoretische oefening; het is een noodzaak voor veerkracht en aanpassingsvermogen in een steeds veranderende omgeving.

De doelstellingen bij het voorspellen
Een voorspelling is een voorspelling over de waarde van een tijdreeksvariabele op een bepaald moment in de toekomst. U kunt bijvoorbeeld een schatting willen maken van de verkoop of vraag van een product voor volgende maand. Een tijdreeks is een reeks getallen die met gelijke tijdsintervallen zijn geregistreerd; bijvoorbeeld de maandelijks geregistreerde verkoop per eenheid. De doelstellingen die u nastreeft wanneer u prognoses maakt, zijn afhankelijk van de aard van uw baan en uw bedrijf. Elke voorspelling is onzeker; in feite is er een reeks mogelijke waarden voor elke variabele die u voorspeld. Waarden in het midden van dit bereik hebben een grotere kans dat ze daadwerkelijk voorkomen, terwijl waarden aan de uiteinden van het bereik minder waarschijnlijk voorkomen.
recente berichten
 Slimme software gepresenteerd op Epicor Insights 2024Smart Software zal dit jaar aanwezig zijn op het Epicor Insights-evenement in Nashville. Als u van plan bent dit jaar aanwezig te zijn, bezoek dan stand #13 of #501 en leer meer over Epicor Smart Inventory Planning and Optimization. . […]
Slimme software gepresenteerd op Epicor Insights 2024Smart Software zal dit jaar aanwezig zijn op het Epicor Insights-evenement in Nashville. Als u van plan bent dit jaar aanwezig te zijn, bezoek dan stand #13 of #501 en leer meer over Epicor Smart Inventory Planning and Optimization. . […] Op zoek naar problemen met uw voorraadgegevensIn deze videoblog wordt een cruciaal aspect van voorraadbeheer in de schijnwerpers gezet: de analyse en interpretatie van voorraadgegevens. De focus ligt specifiek op een dataset van een openbaar vervoersbedrijf met details over reserveonderdelen voor bussen. […]
Op zoek naar problemen met uw voorraadgegevensIn deze videoblog wordt een cruciaal aspect van voorraadbeheer in de schijnwerpers gezet: de analyse en interpretatie van voorraadgegevens. De focus ligt specifiek op een dataset van een openbaar vervoersbedrijf met details over reserveonderdelen voor bussen. […] Big Ass-fans wenden zich tot slimme software naarmate de vraag toeneemtBig Ass Fans is de best verkopende fabrikant van grote ventilatoren ter wereld en levert comfort in ruimtes waar comfort onmogelijk lijkt. BAF had een probleem: hoe kon de productie betrouwbaar worden gepland om aan de vraag te voldoen. BAF ervoer een kloof tussen de prognoses van boekingen en de verzendingen, en dit had gevolgen voor de omzet en de klanttevredenheid. BAF wendde zich tot Smart Software voor hulp. […]
Big Ass-fans wenden zich tot slimme software naarmate de vraag toeneemtBig Ass Fans is de best verkopende fabrikant van grote ventilatoren ter wereld en levert comfort in ruimtes waar comfort onmogelijk lijkt. BAF had een probleem: hoe kon de productie betrouwbaar worden gepland om aan de vraag te voldoen. BAF ervoer een kloof tussen de prognoses van boekingen en de verzendingen, en dit had gevolgen voor de omzet en de klanttevredenheid. BAF wendde zich tot Smart Software voor hulp. […] De kosten van spreadsheetplanningBedrijven die afhankelijk zijn van spreadsheets voor vraagplanning, prognoses en voorraadbeheer worden vaak beperkt door de inherente beperkingen van de spreadsheet. Dit artikel onderzoekt de nadelen van traditionele voorraadbeheerbenaderingen veroorzaakt door spreadsheets en de daarmee samenhangende kosten, en contrasteert deze met de aanzienlijke voordelen die worden behaald door het omarmen van de modernste planningstechnologieën. […]
De kosten van spreadsheetplanningBedrijven die afhankelijk zijn van spreadsheets voor vraagplanning, prognoses en voorraadbeheer worden vaak beperkt door de inherente beperkingen van de spreadsheet. Dit artikel onderzoekt de nadelen van traditionele voorraadbeheerbenaderingen veroorzaakt door spreadsheets en de daarmee samenhangende kosten, en contrasteert deze met de aanzienlijke voordelen die worden behaald door het omarmen van de modernste planningstechnologieën. […] Kan willekeur een bondgenoot zijn in de voorspellingsstrijd?Wanneer we de complexe wereld van de logistiek proberen te begrijpen, speelt willekeur een cruciale rol. Dit introduceert een interessante paradox: in een realiteit waarin precisie en zekerheid worden gewaardeerd, zou de onvoorspelbare aard van vraag en aanbod daadwerkelijk als een strategische bondgenoot kunnen dienen? De zoektocht naar nauwkeurige voorspellingen is niet alleen een academische oefening; het is een cruciaal onderdeel van operationeel succes in tal van sectoren. Voor vraagplanners die moeten anticiperen op de productvraag zijn de gevolgen van het goed of fout doen van de vraag van cruciaal belang. Daarom is het herkennen en benutten van de kracht van willekeur niet slechts een theoretische oefening; het is een noodzaak voor veerkracht en aanpassingsvermogen in een steeds veranderende omgeving. […]
Kan willekeur een bondgenoot zijn in de voorspellingsstrijd?Wanneer we de complexe wereld van de logistiek proberen te begrijpen, speelt willekeur een cruciale rol. Dit introduceert een interessante paradox: in een realiteit waarin precisie en zekerheid worden gewaardeerd, zou de onvoorspelbare aard van vraag en aanbod daadwerkelijk als een strategische bondgenoot kunnen dienen? De zoektocht naar nauwkeurige voorspellingen is niet alleen een academische oefening; het is een cruciaal onderdeel van operationeel succes in tal van sectoren. Voor vraagplanners die moeten anticiperen op de productvraag zijn de gevolgen van het goed of fout doen van de vraag van cruciaal belang. Daarom is het herkennen en benutten van de kracht van willekeur niet slechts een theoretische oefening; het is een noodzaak voor veerkracht en aanpassingsvermogen in een steeds veranderende omgeving. […]

Voorraadoptimalisatie voor fabrikanten, distributeurs en MRO
 Waarom MRO-bedrijven aanvullende software voor serviceonderdelenplanning en inventarisatie nodig hebbenMRO-organisaties bestaan in een breed scala van industrieën, waaronder openbaar vervoer, elektriciteitsbedrijven, afvalwater, waterkracht, luchtvaart en mijnbouw. Om hun werk gedaan te krijgen, gebruiken MRO-professionals Enterprise Asset Management (EAM) en Enterprise Resource Planning (ERP)-systemen. Deze systemen zijn ontworpen om veel taken uit te voeren. Gezien hun kenmerken, kosten en uitgebreide implementatievereisten wordt aangenomen dat EAM- en ERP-systemen het allemaal kunnen. In dit bericht vatten we de behoefte aan aanvullende software samen die zich richt op gespecialiseerde analyses voor voorraadoptimalisatie, prognoses en planning van serviceonderdelen. […]
Waarom MRO-bedrijven aanvullende software voor serviceonderdelenplanning en inventarisatie nodig hebbenMRO-organisaties bestaan in een breed scala van industrieën, waaronder openbaar vervoer, elektriciteitsbedrijven, afvalwater, waterkracht, luchtvaart en mijnbouw. Om hun werk gedaan te krijgen, gebruiken MRO-professionals Enterprise Asset Management (EAM) en Enterprise Resource Planning (ERP)-systemen. Deze systemen zijn ontworpen om veel taken uit te voeren. Gezien hun kenmerken, kosten en uitgebreide implementatievereisten wordt aangenomen dat EAM- en ERP-systemen het allemaal kunnen. In dit bericht vatten we de behoefte aan aanvullende software samen die zich richt op gespecialiseerde analyses voor voorraadoptimalisatie, prognoses en planning van serviceonderdelen. […] De voorspelling is belangrijk, maar misschien niet zoals u denktWaar of niet waar: de prognose is niet van belang voor het voorraadbeheer van reserveonderdelen. Op het eerste gezicht lijkt deze verklaring duidelijk onjuist. Prognoses zijn immers cruciaal voor het plannen van de voorraadniveaus, toch? Het hangt ervan af wat je onder ‘voorspelling’ verstaat. Als u een ouderwetse prognose met één cijfer bedoelt (“de vraag naar artikel CX218b zal volgende week 3 eenheden bedragen en de week erna 6 eenheden”), dan nee. Als je de betekenis van voorspelling verruimt tot een kansverdeling die rekening houdt met onzekerheden in zowel vraag als aanbod, dan ja. […]
De voorspelling is belangrijk, maar misschien niet zoals u denktWaar of niet waar: de prognose is niet van belang voor het voorraadbeheer van reserveonderdelen. Op het eerste gezicht lijkt deze verklaring duidelijk onjuist. Prognoses zijn immers cruciaal voor het plannen van de voorraadniveaus, toch? Het hangt ervan af wat je onder ‘voorspelling’ verstaat. Als u een ouderwetse prognose met één cijfer bedoelt (“de vraag naar artikel CX218b zal volgende week 3 eenheden bedragen en de week erna 6 eenheden”), dan nee. Als je de betekenis van voorspelling verruimt tot een kansverdeling die rekening houdt met onzekerheden in zowel vraag als aanbod, dan ja. […] Waarom MRO-bedrijven zich zorgen moeten maken over overtollige voorraadGeven MRO-bedrijven echt prioriteit aan het verminderen van de overtollige voorraad reserveonderdelen? Vanuit organisatorisch oogpunt blijkt uit onze ervaring dat dit niet noodzakelijk het geval is. Discussies in de bestuurskamer gaan doorgaans over het uitbreiden van wagenparken, het verwerven van nieuwe klanten, het voldoen aan Service Level Agreements (SLA's), het moderniseren van de infrastructuur en het maximaliseren van de uptime. In bedrijfstakken waar activa die worden ondersteund door reserveonderdelen honderden miljoenen kosten of aanzienlijke inkomsten genereren (bijvoorbeeld de mijnbouw of de olie- en gassector), doet de waarde van de voorraad nauwelijks de wenkbrauwen fronsen en hebben organisaties de neiging grote hoeveelheden buitensporige voorraden over het hoofd te zien. […]
Waarom MRO-bedrijven zich zorgen moeten maken over overtollige voorraadGeven MRO-bedrijven echt prioriteit aan het verminderen van de overtollige voorraad reserveonderdelen? Vanuit organisatorisch oogpunt blijkt uit onze ervaring dat dit niet noodzakelijk het geval is. Discussies in de bestuurskamer gaan doorgaans over het uitbreiden van wagenparken, het verwerven van nieuwe klanten, het voldoen aan Service Level Agreements (SLA's), het moderniseren van de infrastructuur en het maximaliseren van de uptime. In bedrijfstakken waar activa die worden ondersteund door reserveonderdelen honderden miljoenen kosten of aanzienlijke inkomsten genereren (bijvoorbeeld de mijnbouw of de olie- en gassector), doet de waarde van de voorraad nauwelijks de wenkbrauwen fronsen en hebben organisaties de neiging grote hoeveelheden buitensporige voorraden over het hoofd te zien. […] Belangrijkste verschillen tussen voorraadplanning voor eindproducten en voor MRO en reserveonderdelenIn het huidige competitieve zakelijke landschap zijn bedrijven voortdurend op zoek naar manieren om hun operationele efficiëntie te verbeteren en meer inkomsten te genereren. Het optimaliseren van het beheer van serviceonderdelen is een vaak over het hoofd gezien aspect dat een aanzienlijke financiële impact kan hebben. Bedrijven kunnen de algehele efficiëntie verbeteren en aanzienlijke financiële opbrengsten genereren door de voorraad reserveonderdelen effectief te beheren. Dit artikel gaat in op de economische implicaties van geoptimaliseerd beheer van serviceonderdelen en hoe investeren in software voor voorraadoptimalisatie en vraagplanning een concurrentievoordeel kan opleveren. […]
Belangrijkste verschillen tussen voorraadplanning voor eindproducten en voor MRO en reserveonderdelenIn het huidige competitieve zakelijke landschap zijn bedrijven voortdurend op zoek naar manieren om hun operationele efficiëntie te verbeteren en meer inkomsten te genereren. Het optimaliseren van het beheer van serviceonderdelen is een vaak over het hoofd gezien aspect dat een aanzienlijke financiële impact kan hebben. Bedrijven kunnen de algehele efficiëntie verbeteren en aanzienlijke financiële opbrengsten genereren door de voorraad reserveonderdelen effectief te beheren. Dit artikel gaat in op de economische implicaties van geoptimaliseerd beheer van serviceonderdelen en hoe investeren in software voor voorraadoptimalisatie en vraagplanning een concurrentievoordeel kan opleveren. […]
