In my previous post in this series on essential concepts, “What is ‘A Good Forecast’”, I discussed the basic effort to discover the most likely future in a demand planning scenario. I defined a good forecast as one that is unbiased and as accurate as possible. But I also cautioned that, depending on the stability or volatility of the data we have to work with, there may still be some inaccuracy in even a good forecast. The key is to have an understanding of how much.
This topic, managing uncertainty, is the subject of post by my colleague Tom Willemain, “The Average is not the Answer”. His post lays out the theory for responsibly confronting the limits of our predictive ability. It’s important to understand how this actually works.
As I briefly touched on at the end of my previous post, our approach begins with something called a “sliding simulation”. We estimate how accurately we are predicting the future by using our forecasting techniques on an older portion of history, excluding the most recent data. We can then compare what we would have predicted for the recent past with our actual real world information about what happened. This is a reliable method to estimate how closely we are predicting future demand.
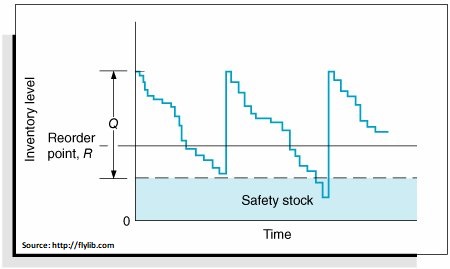
Safety stock, a carefully measured buffer in inventory level we stock above our prediction of most likely demand, is derived from the estimate of forecast error coming out of the “sliding simulation”. This approach to dealing with the accuracy of our forecasts efficiently balances between ignoring the threat of the unpredictable and costly overcompensation.
 In more technical detail: the forecasts errors that are estimated by this sliding simulation process indicate the level of uncertainty. We use these errors to estimate the standard deviation of the forecasts. Now, with regular demand, we can assume the forecasts (which are estimates of future behavior) are best represented by a bell-shaped probability distribution—what statisticians call the “normal distribution”. The center of that distribution is our point forecast. The width of that distribution is the standard deviation of the “sliding simulation” forecast from the known actual values—we obtain this directly from our forecast error estimates.
In more technical detail: the forecasts errors that are estimated by this sliding simulation process indicate the level of uncertainty. We use these errors to estimate the standard deviation of the forecasts. Now, with regular demand, we can assume the forecasts (which are estimates of future behavior) are best represented by a bell-shaped probability distribution—what statisticians call the “normal distribution”. The center of that distribution is our point forecast. The width of that distribution is the standard deviation of the “sliding simulation” forecast from the known actual values—we obtain this directly from our forecast error estimates.
Once we know the specific bell shaped curve associated with the forecast, we can easily estimate the safety stock buffer that is needed. The only input from us is the “service level” that is desired, and the safety stock at that service level can be ascertained. (The service level is essentially a measure of how confident we need to be in our inventory stocking levels, with increasing confidence requiring corresponding expenditures on extra inventory.) Notice, we are assuming that the correct distribution to use is the normal distribution. This is correct for most demand series where you have regular demand per period. It fails when demand is sporadic or intermittent.
In the next piece in this series, I’ll discuss how Smart Forecasts deals with estimating safety stock in those cases of intermittent demand, when the assumption of normality is incorrect.
Nelson Hartunian, PhD, co-founded Smart Software, formerly served as President, and currently oversees it as Chairman of the Board. He has, at various times, headed software development, sales and customer service.

Related Posts

Looking for Trouble in Your Inventory Data
In this video blog, the spotlight is on a critical aspect of inventory management: the analysis and interpretation of inventory data. The focus is specifically on a dataset from a public transit agency detailing spare parts for buses.

Can Randomness be an Ally in the Forecasting Battle?
When we try to understand the complex world of logistics, randomness plays a pivotal role. This introduces an interesting paradox: In a reality where precision and certainty are prized, could the unpredictable nature of supply and demand actually serve as a strategic ally?
The quest for accurate forecasts is not just an academic exercise; it’s a critical component of operational success across numerous industries. For demand planners who must anticipate product demand, the ramifications of getting it right—or wrong—are critical. Hence, recognizing and harnessing the power of randomness isn’t merely a theoretical exercise; it’s a necessity for resilience and adaptability in an ever-changing environment.

The Objectives in Forecasting
A forecast is a prediction about the value of a time series variable at some time in the future. For instance, one might want to estimate next month’s sales or demand for a product item. A time series is a sequence of numbers recorded at equally spaced time intervals; for example, unit sales recorded every month. The objectives you pursue when you forecast depend on the nature of your job and your business. Every forecast is uncertain; in fact, there is a range of possible values for any variable you forecast. Values near the middle of this range have a higher likelihood of actually occurring, while values at the extremes of the range are less likely to occur.
Recent Posts
 Irregular OperationsThis blog is about “irregular operations.” Smart Software is in the process of adapting our products to help you cope with your own irregular ops. This is a preview. […]
Irregular OperationsThis blog is about “irregular operations.” Smart Software is in the process of adapting our products to help you cope with your own irregular ops. This is a preview. […] Smart Software to Present at Epicor Insights 2024Smart Software will present at this year's Epicor Insights event in Nashville. If you plan to attend this year, please join us at booth #13 or #501, and learn more about Epicor Smart Inventory Planning and Optimization. . […]
Smart Software to Present at Epicor Insights 2024Smart Software will present at this year's Epicor Insights event in Nashville. If you plan to attend this year, please join us at booth #13 or #501, and learn more about Epicor Smart Inventory Planning and Optimization. . […] Looking for Trouble in Your Inventory DataIn this video blog, the spotlight is on a critical aspect of inventory management: the analysis and interpretation of inventory data. The focus is specifically on a dataset from a public transit agency detailing spare parts for buses. […]
Looking for Trouble in Your Inventory DataIn this video blog, the spotlight is on a critical aspect of inventory management: the analysis and interpretation of inventory data. The focus is specifically on a dataset from a public transit agency detailing spare parts for buses. […] Big Ass Fans Turns to Smart Software as Demand Heats UpBig Ass Fans is the best-selling big fan manufacturer in the world, delivering comfort to spaces where comfort seems impossible. BAF had a problem: how to reliably plan production to meet demand. BAF was experiencing a gap between bookings forecasts vs. shipments, and this was impacting revenue and customer satisfaction BAF turned to Smart Software for help. […]
Big Ass Fans Turns to Smart Software as Demand Heats UpBig Ass Fans is the best-selling big fan manufacturer in the world, delivering comfort to spaces where comfort seems impossible. BAF had a problem: how to reliably plan production to meet demand. BAF was experiencing a gap between bookings forecasts vs. shipments, and this was impacting revenue and customer satisfaction BAF turned to Smart Software for help. […] The Cost of Spreadsheet PlanningCompanies that depend on spreadsheets for demand planning, forecasting, and inventory management are often constrained by the spreadsheet’s inherent limitations. This post examines the drawbacks of traditional inventory management approaches caused by spreadsheets and their associated costs, contrasting these with the significant benefits gained from embracing state-of-the-art planning technologies. […]
The Cost of Spreadsheet PlanningCompanies that depend on spreadsheets for demand planning, forecasting, and inventory management are often constrained by the spreadsheet’s inherent limitations. This post examines the drawbacks of traditional inventory management approaches caused by spreadsheets and their associated costs, contrasting these with the significant benefits gained from embracing state-of-the-art planning technologies. […]

Inventory Optimization for Manufacturers, Distributors, and MRO
 Why MRO Businesses Need Add-on Service Parts Planning & Inventory SoftwareMRO organizations exist in a wide range of industries, including public transit, electrical utilities, wastewater, hydro power, aviation, and mining. To get their work done, MRO professionals use Enterprise Asset Management (EAM) and Enterprise Resource Planning (ERP) systems. These systems are designed to do a lot of jobs. Given their features, cost, and extensive implementation requirements, there is an assumption that EAM and ERP systems can do it all. In this post, we summarize the need for add-on software that addresses specialized analytics for inventory optimization, forecasting, and service parts planning. […]
Why MRO Businesses Need Add-on Service Parts Planning & Inventory SoftwareMRO organizations exist in a wide range of industries, including public transit, electrical utilities, wastewater, hydro power, aviation, and mining. To get their work done, MRO professionals use Enterprise Asset Management (EAM) and Enterprise Resource Planning (ERP) systems. These systems are designed to do a lot of jobs. Given their features, cost, and extensive implementation requirements, there is an assumption that EAM and ERP systems can do it all. In this post, we summarize the need for add-on software that addresses specialized analytics for inventory optimization, forecasting, and service parts planning. […] The Forecast Matters, but Maybe Not the Way You ThinkTrue or false: The forecast doesn't matter to spare parts inventory management. At first glance, this statement seems obviously false. After all, forecasts are crucial for planning stock levels, right? It depends on what you mean by a “forecast”. If you mean an old-school single-number forecast (“demand for item CX218b will be 3 units next week and 6 units the week after”), then no. If you broaden the meaning of forecast to include a probability distribution taking account of uncertainties in both demand and supply, then yes. […]
The Forecast Matters, but Maybe Not the Way You ThinkTrue or false: The forecast doesn't matter to spare parts inventory management. At first glance, this statement seems obviously false. After all, forecasts are crucial for planning stock levels, right? It depends on what you mean by a “forecast”. If you mean an old-school single-number forecast (“demand for item CX218b will be 3 units next week and 6 units the week after”), then no. If you broaden the meaning of forecast to include a probability distribution taking account of uncertainties in both demand and supply, then yes. […] Why MRO Businesses Should Care About Excess InventoryDo MRO companies genuinely prioritize reducing excess spare parts inventory? From an organizational standpoint, our experience suggests not necessarily. Boardroom discussions typically revolve around expanding fleets, acquiring new customers, meeting service level agreements (SLAs), modernizing infrastructure, and maximizing uptime. In industries where assets supported by spare parts cost hundreds of millions or generate significant revenue (e.g., mining or oil & gas), the value of the inventory just doesn’t raise any eyebrows, and organizations tend to overlook massive amounts of excessive inventory. […]
Why MRO Businesses Should Care About Excess InventoryDo MRO companies genuinely prioritize reducing excess spare parts inventory? From an organizational standpoint, our experience suggests not necessarily. Boardroom discussions typically revolve around expanding fleets, acquiring new customers, meeting service level agreements (SLAs), modernizing infrastructure, and maximizing uptime. In industries where assets supported by spare parts cost hundreds of millions or generate significant revenue (e.g., mining or oil & gas), the value of the inventory just doesn’t raise any eyebrows, and organizations tend to overlook massive amounts of excessive inventory. […] Top Differences Between Inventory Planning for Finished Goods and for MRO and Spare PartsIn today’s competitive business landscape, companies are constantly seeking ways to improve their operational efficiency and drive increased revenue. Optimizing service parts management is an often-overlooked aspect that can have a significant financial impact. Companies can improve overall efficiency and generate significant financial returns by effectively managing spare parts inventory. This article will explore the economic implications of optimized service parts management and how investing in Inventory Optimization and Demand Planning Software can provide a competitive advantage. […]
Top Differences Between Inventory Planning for Finished Goods and for MRO and Spare PartsIn today’s competitive business landscape, companies are constantly seeking ways to improve their operational efficiency and drive increased revenue. Optimizing service parts management is an often-overlooked aspect that can have a significant financial impact. Companies can improve overall efficiency and generate significant financial returns by effectively managing spare parts inventory. This article will explore the economic implications of optimized service parts management and how investing in Inventory Optimization and Demand Planning Software can provide a competitive advantage. […]