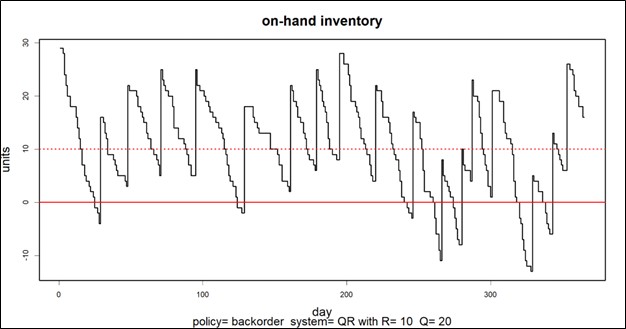
Empezaré con una confesión: soy un tipo de algoritmos. Mi corazón vive en la “sala de máquinas” de nuestro software, donde los cálculos ultrarrápidos van y vienen a través de la nube de AWS, generando escenarios de oferta y demanda que se utilizan para guiar decisiones importantes sobre el pronóstico de la demanda y la gestión de inventario.
Pero reconozco que el objetivo de todo ese hermoso y furioso cálculo es el cerebro del jefe, la persona responsable de garantizar que la demanda de los clientes se satisfaga de la manera más eficiente y rentable. Entonces, este blog trata sobre Analítica operativa inteligente (SOA), que crea informes para la gestión. O, como se les llama en el ejército, sit-reps.
Todos los cálculos guiados por los planificadores que utilizan nuestro software finalmente se resumen en los informes SOA para la gestión. Los informes se centran en cinco áreas: análisis de inventario, desempeño del inventario, tendencias del inventario, desempeño de los proveedores y anomalías de la demanda.
Análisis de inventario
Estos informes controlan los niveles actuales de inventario e identifican áreas que necesitan mejoras. La atención se centra en los recuentos de inventario actuales y su estado (disponible, en tránsito, en cuarentena), rotación de inventario y excesos frente a escasez.
Rendimiento del inventario
Estos informes rastrean indicadores clave de rendimiento (KPI), como tasas de cumplimiento, niveles de servicio y costos de inventario. Los cálculos analíticos en otras partes del software lo guían hacia el logro de sus objetivos de KPI mediante el cálculo de predicciones clave de rendimiento (KPP) basadas en configuraciones recomendadas para, por ejemplo, puntos de reorden y cantidades de pedidos. Pero a veces ocurren sorpresas o las políticas operativas no se ejecutan según lo recomendado, por lo que siempre habrá algún desfase entre los KPP y los KPI.
Tendencias del inventario
Saber dónde están las cosas hoy es importante, pero también es valioso ver dónde están las tendencias. Estos informes revelan tendencias en la demanda de artículos, eventos de desabastecimiento, días promedio disponibles, tiempo promedio de envío y más.
Rendimiento de los proveedores
Su empresa no puede rendir al máximo si sus proveedores la están hundiendo. Estos informes monitorean el desempeño de los proveedores en términos de la precisión y rapidez en el cumplimiento de los pedidos de reabastecimiento. Cuando tienes varios proveedores para el mismo artículo, te permiten compararlos.
Anomalías de la demanda
Todo su sistema de inventario está impulsado por la demanda y todos los parámetros de control de inventario se calculan después de modelar la demanda de los artículos. Entonces, si sucede algo extraño en el lado de la demanda, debe estar atento y prepararse para volver a calcular cosas como mínimos y máximos para elementos que comienzan a actuar de manera extraña.
Resumen
El punto final de todos los cálculos masivos de nuestro software es el panel que muestra a la administración qué está pasando, qué sigue y dónde centrar la atención. Smart Inventory Analytics es la parte de nuestro ecosistema de software dirigido al C-Suite de su empresa.
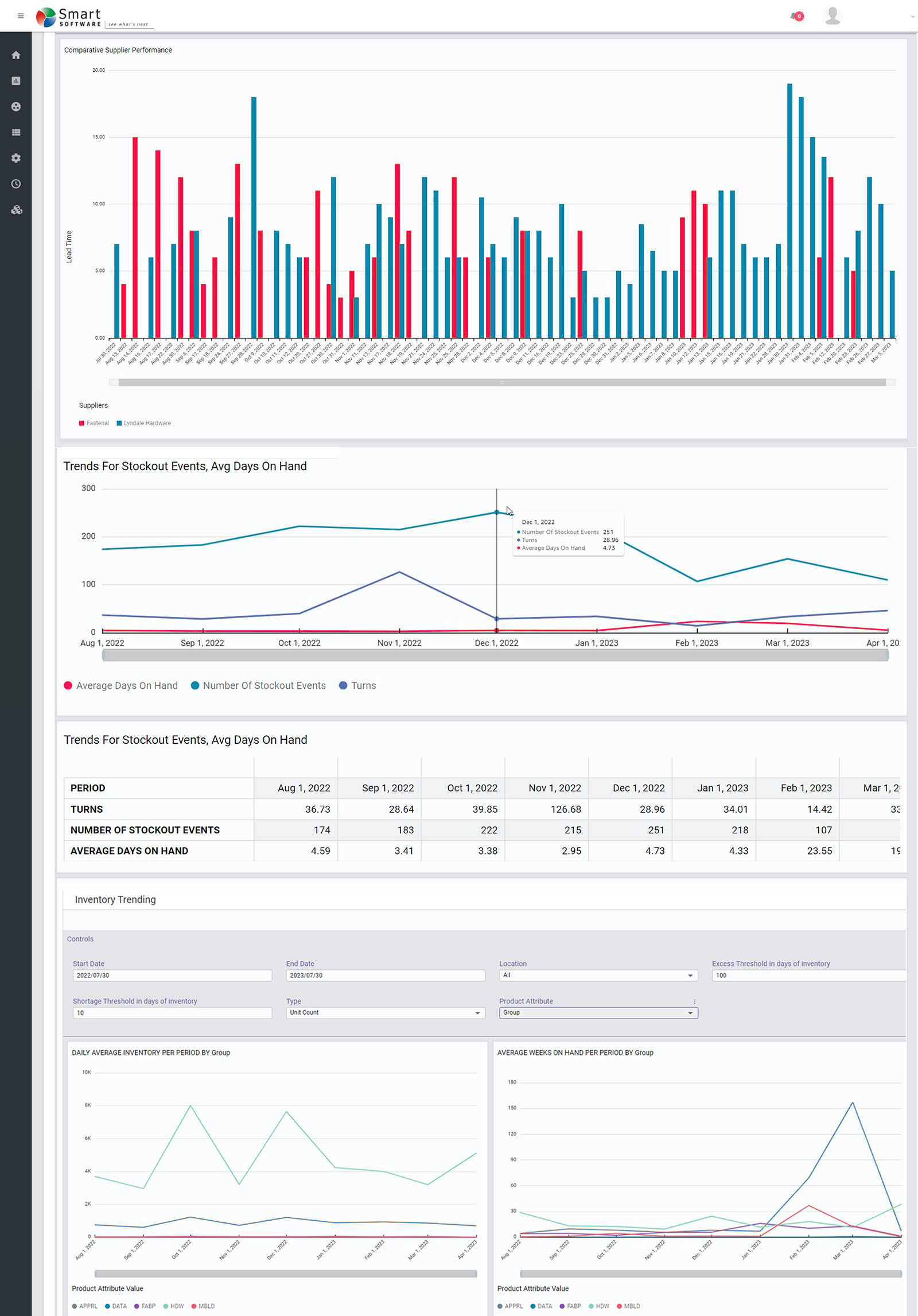
Figura 1: Algunos informes de muestra en forma gráfica